대규모 데이터 처리와 디버깅
- 디버깅의 어려움: 작은 데이터셋에서는 작동하던 것이 큰 규모에서는 메모리 관리 문제(버퍼링, 객체 생성), 과도한 중간 데이터, 손상된 입력 레코드 등으로 인해 실패할 수 있음
- 데이터의 현실: 실제 데이터는 지저분하고(messy) 일관성이 없음
- 데이터센터: 데이터센터 자체가 하나의 거대한 컴퓨터로 비유됨.
- MapReduce의 한계: 맵리듀스는 훌륭하지만, 데이터센터 컴퓨터를 제어하기엔 '어셈블리'처럼 너무 저수준의 방식임.
고수준 언어의 필요성
- Hadoop과 Java: 하둡은 대용량 데이터 처리에 좋지만, 모든 것을 Java로 작성하는 것은 장황하고(verbose) 느림. 데이터 과학자들은 Java 작성을 선호하지 않음.
- 해결책: 더 높은 수준의 언어와 컴파일러를 설계하는 것.
- Hive와 Pig의 탄생:
- Facebook: SQL이 필요했음 → Hive 개발.
- Yahoo: 스크립팅 언어가 필요했음 → Pig 개발.
- 존재 이유: 전통적인 데이터베이스로 처리할 수 없을 만큼 데이터의 양이 많기 때문.
- 공통 개념: 고수준 언어(HiveQL, Pig Latin)를 제공하며, 이 언어들은 하둡 맵리듀스 작업으로 컴파일되어 실행됨.
- Hive: 데이터 웨어하우징 애플리케이션으로, SQL 변형인 HiveQL을 사용하며 HDFS에 테이블을 저장함 (Facebook 개발).
- Pig: 대규모 데이터 처리를 위한 시스템으로, 데이터 흐름 언어인 Pig Latin을 사용함 (Yahoo 개발).
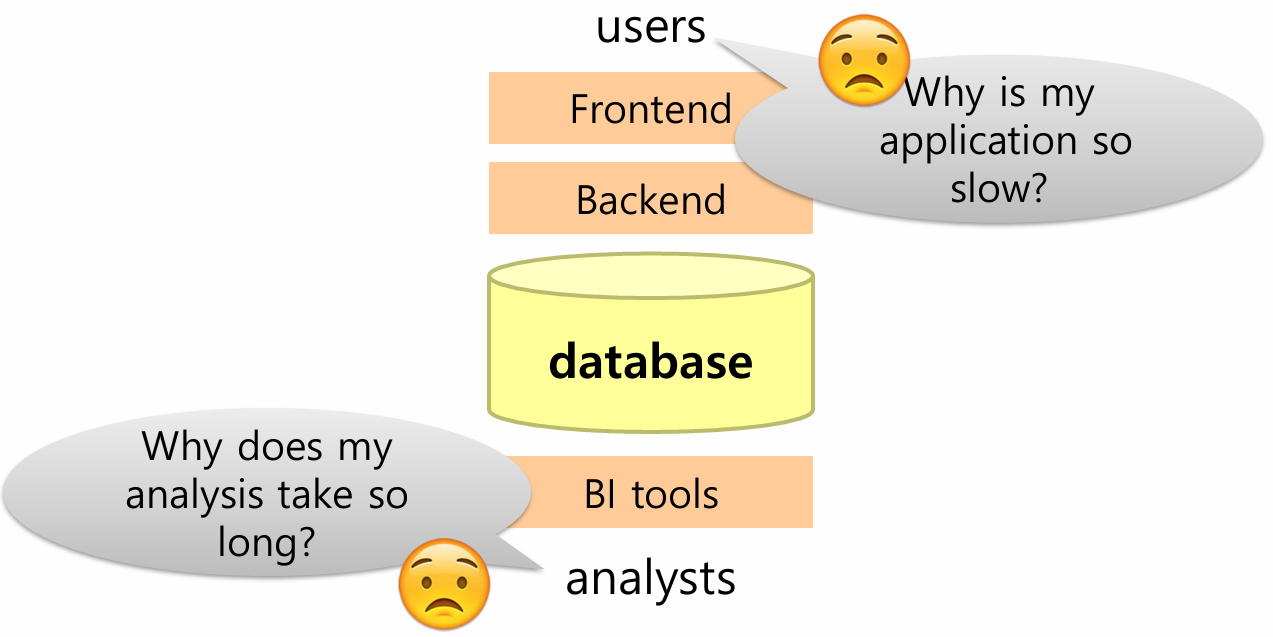
데이터베이스 워크로드
- 두 가지 불만:
- 사용자 (Users): "왜 내 애플리케이션이 느리지?" (Frontend/Backend) .
- 분석가 (Analysts): "왜 내 분석이 오래 걸리지?" (BI tools)
- OLTP (Online Transaction Processing):
- 용도: 사용자 대면 서비스 (예: 전자상거래, 은행).
- 특징: 실시간, 저지연, 높은 동시성.
- 작업: 작고 표준화된 트랜잭션 쿼리 (소량의 데이터에 대한 무작위 읽기, 쓰기, 업데이트). 데이터 변경(업데이트, 삭제)이 잦음.
- OLAP (Online Analytical Processing):
- 용도: 백엔드 처리 (예: 비즈니스 인텔리전스, 데이터 마이닝).
- 특징: 배치 작업, 낮은 동시성.
- 작업: 복잡한 분석 쿼리 (대량의 데이터 테이블 스캔). 데이터 변경이 거의 없음.
- OLTP와 OLAP의 공존 문제: 두 워크로드를 함께 사용하면 충돌하는 데이터 접근 패턴, 비효율적인 메모리 관리, 예측 불가능한 지연 시간(latency) 문제가 발생함.
- 해결책: 데이터 웨어하우스(Data Warehouse) 구축.
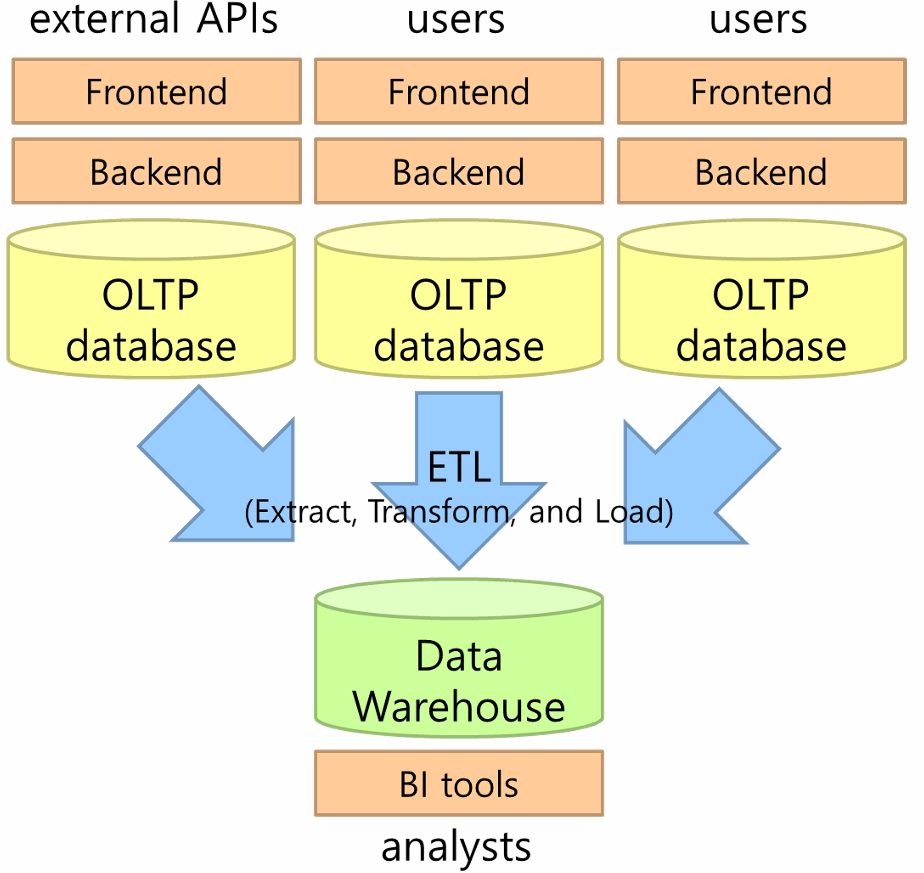
데이터 웨어하우스와 ETL
- 아키텍처: OLTP용 데이터베이스(사용자 트랜잭션 처리)와 Data Warehouse용 OLAP 데이터베이스(분석용)를 분리하여 구축함.
- 데이터 흐름: 여러 OLTP 지점에서 발생한 트랜잭션 데이터를 일정한 주기(예: 일주일)마다 데이터 웨어하우스로 전송함.
- ETL (Extract, Transform, Load): 이 전송 과정에서 ETL(추출, 변환, 적재) 과정이 필수적임.
- Extract (추출): 소스(OLTP DB)에서 데이터를 가져옴.
- Transform (변환): 데이터를 정리하고(이상한 데이터 제거), 스키마를 통합/변환하며 무결성을 확인함.
- Load (적재): 변환된 데이터를 데이터 웨어하우스에 적재함.
- 데이터 웨어하우스 특징:
- 데이터 분석만을 위해 사용되며, OLTP 시스템에 영향을 미치지 않음 (독립적).
- 업데이트가 거의 발생하지 않아 트랜잭션 관리가 불필요하며, 데이터 정렬이 상대적으로 쉬움.

OLAP 큐브 연산
- OLAP 큐브: 다차원(예: 시간, 제품, 상점)으로 데이터를 표현하는 모델.
- 주요 연산:
- Roll-up (롤업): 낮은 수준의 상세 데이터(도시)를 높은 수준(국가)으로 집계함. GROUP BY 집계 함수에 유용.
- Drill-down (드릴다운): 높은 수준(분기)에서 낮은 수준(월)으로 데이터를 세분화함.
- Slice (슬라이스): 하나의 차원 값을 고정하여(예: time = "Q1") 데이터를 자름.
- Dice (다이스): 여러 차원에서 특정 범위나 값들을 선택하여(예: location = "Toronto" or "Vancouver" AND time = "Q1" or "Q2") 하위 큐브를 만듦.
- Pivot (피벗): 데이터 큐브의 축을 회전시켜 다른 관점으로 데이터를 봄.
- 큐브의 과제: OLAP 연산은 근본적으로 많은 조인, group-by, 집계를 포함함.
- 해결책 (Cube materialization): 반복 작업을 피하기 위해 요약 데이터를 미리 계산하고 저장(구체화)함. 하지만 전체 큐브를 구체화하는 것은 비현실적일 수 있어, 무엇을/언제 구체화할지 결정해야 함.
Facebook 사례와 Hadoop의 부상

- Facebook의 한계: 첫날 400GB의 클릭 스트림 데이터가 발생하자, Oracle 데이터 웨어하우스는 하루치 데이터를 집계하는 데 24시간 이상이 소요됨.
- ETL vs. ELT:
- ETL: 데이터 추출(E) → 중간에서 변환(T) → 하둡에 적재(L).
- ELT: 데이터 추출(E) → 원본(Raw) 그대로 하둡에 적재(L) → 나중에 하둡의 강력한 성능을 이용해 변환(T).
- Hadoop의 필요성: 하둡에 저장된 데이터는 너무 원본(Raw)이라 SQL이 아닌 Pig, Spark 같은 복잡한 프로그래밍이 필요할 수 있음. 이는 BI 도구로 빠른 리포트를 보려는 분석가들과 맞지 않을 수 있음.
- 환경의 변화:
- 디스크 비용이 급락하여, 무엇을 버릴지 고민하는 비용보다 모든 것을 저장하는 비용이 더 저렴해짐.
- 소셜 미디어와 사용자 생성 콘텐츠(UGC)의 증가로 데이터 볼륨이 폭증함.
- 데이터베이스의 한계:
- DB는 데이터가 구조화되어 있고, 깨끗하며, 수행할 쿼리를 미리 알 때 적합함.
- DB는 데이터 구조가 없거나(비구조화), 데이터가 지저분하고(messy), 무엇을 찾을지 모를 때 부적합함.
- Hadoop의 이점 (Data Lake):
- 미리 스키마를 알 필요가 없음.
- 데이터 수집 속도(ingest rate)가 훨씬 빠름.
- 하둡은 **'데이터 레이크(Data Lake)'**처럼 구조화, 비구조화(로그, 이미지, 텍스트) 등 모든 원본 데이터를 가공 없이 저장함.
Schema-on-Read vs. Schema-on-Write

- Schema-on-Write (전통적 DB, RDB):
- 순서: 데이터 수집 → 스키마 적용 (PK, 제약조건 등) → 데이터 쓰기 → 분석.
- 특징: 데이터를 쓸 때(Write) 스키마를 적용함. ETL 과정을 통해 스키마에 맞춰 데이터를 저장.
- 장점: 읽기(Read)가 빠름. 표준 및 거버넌스에 유리.
- 단점: 적재(Load)가 상대적으로 느림.
- Schema-on-Read (Hadoop):
- 순서: 데이터 수집 → 데이터 쓰기 (Raw 저장) → 스키마 적용 → 분석.
- 특징: 데이터를 읽을 때(Read) 스키마를 적용함. 원본 데이터를 먼저 저장하고, 코드로 스키마를 적용.
- 장점: 적재(Load)가 빠름. 유연성과 민첩성이 높음.
- 단점: 읽기(Read) 시점에 스키마를 적용하므로 읽기가 느려질 수 있음.
MapReduce vs. 병렬 데이터베이스
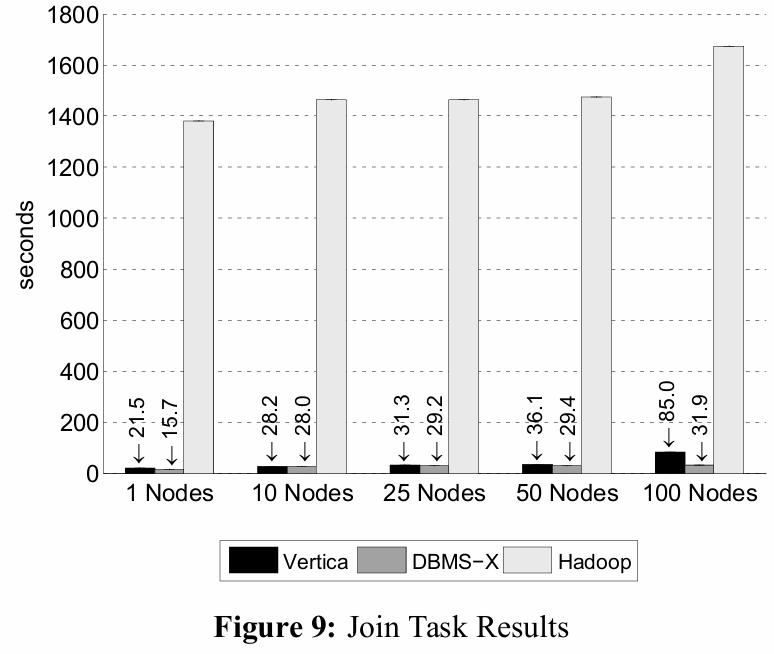
- SIGMOD 2009년 논문 비교: MapReduce(MR)와 병렬 DBMS(예: Vertica)의 성능을 비교함.
- 쿼리 성능: Grep(검색), Select(선택), Aggregation(집계), Join(조인)과 같은 SQL 분석 작업에서는 병렬 DBMS가 Hadoop(MR)보다 압도적으로 빠른 성능을 보임.
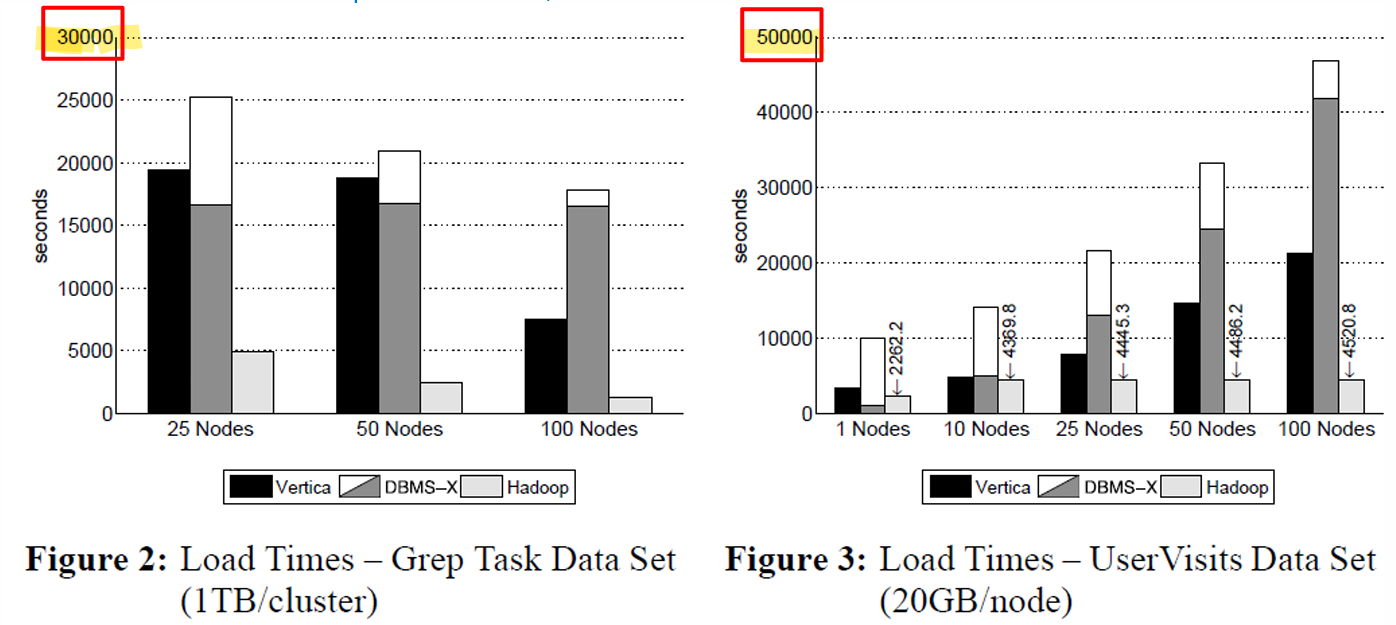
- 데이터 로딩 성능 (반전):
- 데이터 로딩(Loading) 시간은 정반대의 결과가 나옴.
- Hadoop(Schema-on-Read)이 병렬 DBMS(Schema-on-Write)보다 압도적으로 데이터 적재 속도가 빠름.
- 병렬 DB는 로딩 시간이 하둡 분석 시간의 5~50배에 달할 수 있음.
- 핵심 트레이드오프:
- 데이터셋은 생성된 후 한두 번 처리되고 버려지는 경우가 많음.
- 병렬 DB: SQL 쿼리(읽기) 성능은 최고지만, 데이터 로딩(쓰기)이 매우 느리고 구조화된 데이터만 받음.
- Hadoop: 데이터 로딩(쓰기)이 'Schema-on-Read' 덕분에 매우 빠르고, 비구조화 데이터도 유연하게 저장함. 반면 쿼리 성능은 전문 DB보다 비효율적임.
- 현대적 전략: 일단 모든 원본 데이터를 하둡(데이터 레이크)에 빠르게 쏟아붓고(Loading), 나중에 Hive, Spark SQL 또는 전문 DB로 옮겨 분석함.



'CLAUD COMPUTERING' 카테고리의 다른 글
| [클라우드 컴퓨터링] NOSQL 데이터베이스 (0) | 2025.11.06 |
|---|---|
| [딥러닝] 텐서플로우의 GradientTape (자동 미분) (0) | 2025.10.30 |
| [클라우드 컴퓨터링] MapReduce 데이터 흐름과 API (0) | 2025.10.21 |
| [클라우드 컴퓨터링] MapReduce 데이터 관리 (0) | 2025.10.16 |
| [클라우드 컴퓨터링] Haddop의 데이터 처리를 위한 MapReduce (0) | 2025.10.14 |